

SHOT: Unique Signatures of Histograms for Local Surface Description
The ability of computing similarities between 3D surfaces (surface matching) is a key for computer vision tasks such as 3D object recognition and surface alignment. These tasks find numerous applications in fields such as robotics, automation, biometric systems, reverse engineering, search in 3D object databases. The most popular trend for surface matching exploits a compact local representation of the input data, known as descriptor, and shares basic motivations with the successful approaches for matching 2D images that rely on local invariant features. Local correspondences established by matching 3D descriptors (Fig. 1) can then be used to solve higher level tasks such as 3D object recognition. This approach allows for dealing effectively with issues such as occlusion, clutter and changes of viewpoint. As a result, a variety of proposals for 3D descriptors can be found in recent literature.
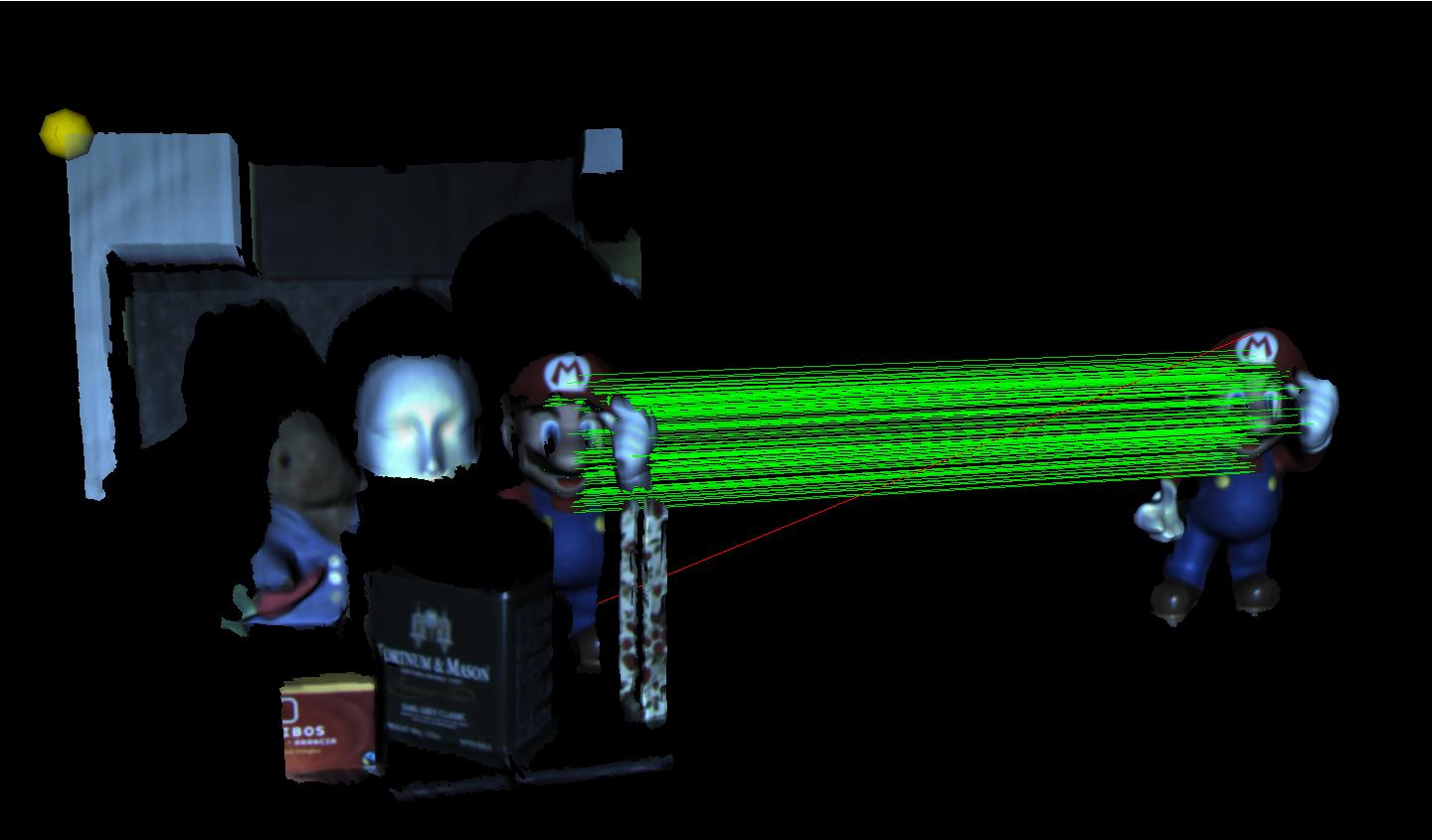
Fig. 1
Our first contribution is a specific study upon local 3D Reference Frames (RFs) for 3D descriptors. We have carried out an analysis of repeatability and robustness on proposed local RFs, and provided experiments that demonstrate the strong impact of the choice of the RF on the performance of a 3D descriptor. Given the impact of such a choice, our second contribution is a robust local RF that, unlike all other proposals, is unique and unambiguous. Our third contribution is a novel 3D descriptor. Its design, inspired by an analysis of the successful choices performed in the related field of 2D descriptors, has been explicitly conceived to achieve computational efficiency, descriptive power and robustness.
The design of the descriptor naturally allows for simultaneously encoding multiple cues. e.g. shape and texture. In [2] we studied what are the most effective and efficient ways to include texture information in the descriptor. The inclusion of the texture cue results in more effective descriptions, with limited impact on efficiency. Therefore, the extended version of our descriptor qualifies as a natural tool to attain point-to-point correspondences in RGB-D data, such as that provided by the recently released Microsoft Kinect.
Finally, in [3] we summarize all the research activity carried out on this topic by presenting all the details and pseudo-code to reproduce the methods, an enriched and revised taxonomy of 3D descriptors, and an extended comparative evaluation which adds to the previous results three additional prominent proposals, a novel dataset acquired by means of a Kinect sensor and a study on the performance of the considered descriptors in a shape retrieval scenario.
Dataset
It is possible to download all the datasets used for the experimental evaluation in [1], [2] and [3]. All files contained in the datasets are in PLY format.
Descriptor Matching
All the datasets in this section are relative to the descriptor matching experiments of our paper. They include several models and scenes, containing some models as well as other objects (clutter). Clutter objects and models are partially occluding each other.
The datasets also include, for each scene:
- a "Config" file (ConfigSceneXX.ini), defining the number of models and the scene file name for that scene. It also defines, for each model present in that scene, the model file names and the model groundtruth files.
- as many groundtruth files as the models in that scenes (SceneXX-rsY.xf), each defining the rotation and translation to be applied to each model in order to align it to its corresponding instance in each scene.
Descriptor Matching - Dataset 1 & 2 (Stanford)
These datasets, created from some of the models belonging to the Stanford 3D Scanning Repository, are composed of 6 models and 45 scenes. Each of the 45 scenes contains a subset of the 6 models randomly chosen and randomly rotated and translated so to create clutter conditions. In particular, out of the 45 scenes the dataset contains:
- 15 scenes with 3 models each
- 15 scenes with 4 models each
- 15 scenes with 5 models each
Dataset 1 is used in [1] for Experiment 1 (with additional Gaussian noise on each scene, at 3 different levels of noise) and dataset 2 in Experiment 2.
The models of these datasets can be downloaded either as:
The scenes of dataset 1 can be downloaded either as:
The scenes of dataset 2 can be downloaded either as:
Descriptor Matching - Dataset 3 (Spacetime Stereo)
This dataset, acquired in our lab by means of the Spacetime Stereo technique, is composed of 8 models and 15 scenes, divided into 4 sets as follows:
- Set 1: 2 models, 4 scenes
- Set 2: 2 models, 4 scenes
- Set 3: 2 models, 4 scenes
- Set 4: 2 models, 3 scenes
The dataset can be downloaded either as:
Descriptor Matching - Dataset 4 (Spacetime Stereo Texture)
This dataset, acquired in our lab by means of the Spacetime Stereo technique, is composed of 8 models and 16 scenes, divided into 4 sets as follows:
- Set 1: 2 models, 4 scenes
- Set 2: 2 models, 4 scenes
- Set 3: 2 models, 4 scenes
- Set 4: 2 models, 4 scenes
This dataset includes models with highly similar shapes but different textures. It has been used in [2] to assess the benefits brought in by the use of the color cue.
The dataset can be downloaded either as:
Descriptor Matching - Dataset 5 (Kinect)
This dataset, used in [3] and acquired in our lab by means of the Microsoft Kinect sensor, is composed of 6 models and 16 scenes (15 test scenes + 1 tuning scene).
The dataset can be downloaded either as:
Reconstruction
These datasets are composed of several views of some objects. They are used to perform 3D reconstruction experiments in [1].
Reconstruction - Space Time Views
This dataset, acquired in our lab by means of the Microsoft Space Time technique, is composed of several views of 2 objects ("Mario" and "Squirell"). Only the "Mario" views were used in [1].
The dataset can be downloaded either as:
Reconstruction - Kinect Views
This dataset, acquired in our lab by means of the Microsoft Kinect sensor, is composed of several views of 2 objects ("Frog" and "Duck").
The dataset can be downloaded either as:
NOTE
- If you use the datasets for any kind of scientific work or publication, we kindly request to appropiately cite this webpage and [1, 2]. See the Stanford 3D Scanning Repository webpage for conditions concerning use and redistribution of Dataset "Stanford".
Code
We have a freely available implementation of the SHOT descriptor within a MS VS 2005/2010 environment. To obtain the SHOT code, please write to (federico DOT tombari AT unibo DOT it) or (samuele DOT salti AT unibo DOT it) and we will provide to send it to you.
1.3.2016: A MATLAB version of the SHOT descriptor is also available upon request. (Thanks to Dr. Emanuele Rodolà for porting to the MATLAB environment)
References
| [1] | F. Tombari *, S. Salti *, L. Di Stefano, "Unique Signatures of Histograms for Local Surface Description", 11th European Conference on Computer Vision (ECCV), September 5-11, Hersonissos, Greece, 2010. [PDF] |
| [2] | F. Tombari, S. Salti, L. Di Stefano, "A combined texture-shape descriptor for enhanced 3D feature matching", IEEE International Conference on Image Processing (ICIP), September 11-14, Brussels, Belgium, 2011. [PDF] |
| [3] | S. Salti, F. Tombari, L. Di Stefano, "SHOT: Unique Signatures of Histograms for Surface and Texture Description", Computer Vision and Image Understanding, May, 2014. [PDF] |
| (* indicates equal contribution) |